gitの使用方法メモ
mercurialからの類推で git を使おうとしたが挫折。
gitの説明書を読んで基本的な概念と操作をまとめてみる。
参照した説明書は次の2つ。
動作は git version 1.7.10.4 で確認した。
基礎概念
- コミット
- ファイルツリーのある時点でのスナップショット。mercurialでのchangeset。コミットは、61c4efc3〜 のような16進数の番号が付けられている。gitコマンドの引数でコミットを指定するときはこの番号を使う。
- ブランチ
- 開発ライン。コミットの連なり。動作上は、コミットを指すポインタと考えてよい。その意味では、ブランチは、一連のコミットの最新を指していると考えることができる。コミットの連なりは途中から分岐できるため、複数のブランチを持つことができる。gitコマンドでコミットを指定する箇所には、基本的にブランチ名も指定できる(ブランチの最新コミットを指定したことになる)。
- HEAD
- 現在のブランチ。作業ディレクトリには、いずれか1つのブランチを選択して、その最新コミットの内容を取り出す。HEADは、作業ディレクトリの取り出し元となったコミットともいえる。mercurialのheadとは異なる。gitコマンドでブランチ名やコミットを指定する箇所には、基本的に"HEAD"を指定できる(作業ディレクトリの取り出し元コミットを指定したことになる)。
ファイルの編集とリポジトリへの登録
- ブランチを選択して、ファイル一式を作業ディレクトリに取り出す(checkout)。
- ファイルを編集する。または、追加・削除する。
- 変更後のファイルを「ステージング領域」に登録する。または、ステージング領域に新規ファイルを登録したり、ファイルの削除を登録する。
- 2, 3 を必要なだけ繰り返す。
- ステージング領域の内容をcommitしてコミットを作成する。
同じブランチを対象に作業する限り、1は再実行しなくてよい。
git の help に出現する用語 "index" はステージング領域を指す(厳密には別物かもしれないが・・・)。
作業対象のブランチの切り替え (checkout)
git checkout <ローカルブランチ名>
ローカルブランチの代わりにリモートブランチやコミット(の番号)も指定できる。ある時点でのファイル一式を作業ディレクトリに取得してビルドしたり実行確認するのに利用できる。この場合、作業ディレクトリはどのブランチにも属さない状態(detached HEAD)になる。この状態でコミットしても、どのブランチにも影響を与えない。既存のブランチを誤って更新してしまう心配がない。
detached HEADの状態でもコミットは可能。ただし、コミット番号を覚えておかないと、別のブランチに切り替え(checkout)した後に戻ってこられなくなる。detached HEADな状態で今のコミットを新たなブランチとして登録するには、
git checkout -b <新しいブランチ名>
detached HEADな状態でプログラムの修正を試し、うまく行けばコミットし(場合によってはブランチ名を付け)、その後メインのブランチに戻って、そのコミットをマージする、という使い方もできる。
ステージング領域への登録、commit、変更の取り消し
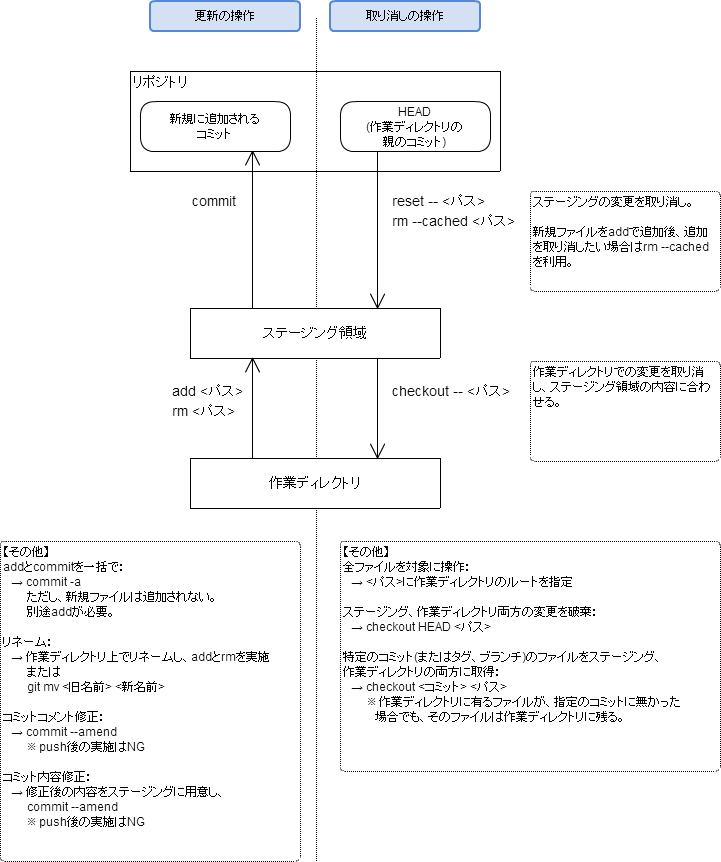
備考
- checkoutコマンドは次の2つの機能を持っているため、混同しないように注意。
- 引数にパスを指定しない → 作業対象のブランチを選択する。
- 引数にパスを指定する → 作業対象のブランチは変更せず、指定のコミット、ブランチ、またはステージング領域からファイルを作業ディレクトリ(またはステージング領域)に取得。
- 「checkout -- <パス>」などの -- は、後続の引数がパスであることを示すマークであって、単独の引数として意味があるわけではない(コミット名やブランチ名を表しているわけではない)。
diff
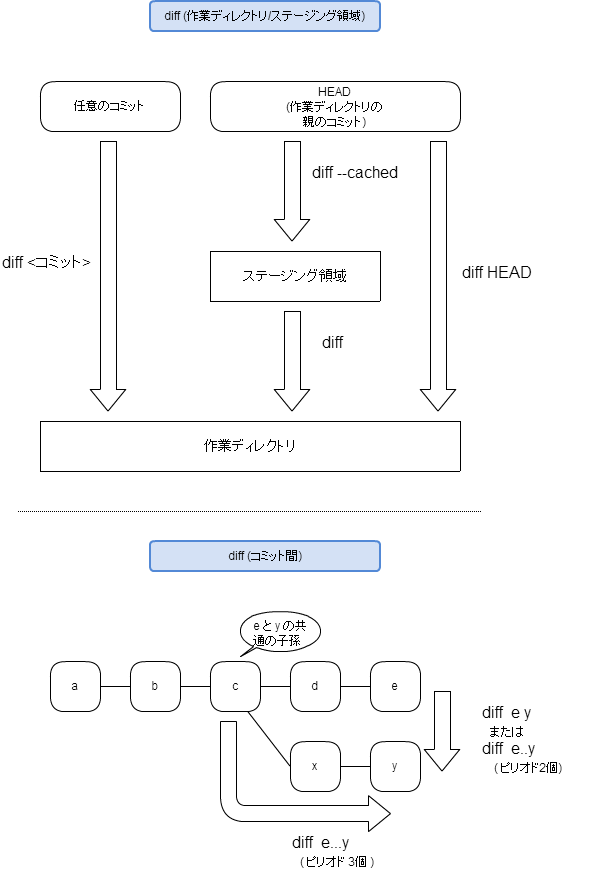
マージ作業中のdiffについては、後述する。
別リポジトリとの連携、マージ
別リポジトリのcloneと、ローカルブランチ・リモートブランチ
cloneによって作られるリポジトリは、次の点で、clone元のリポジトリとは内容が異なる。
- リポジトリをcloneすると、clone元リポジトリのブランチは、自分のリポジトリには「リモートブランチ」として登録される。
- commitコマンドにより更新できるのは「ローカルブランチ」である。「リモートブランチ」は直接は更新できない。
- cloneすると、ローカルブランチも自動的に作成される。
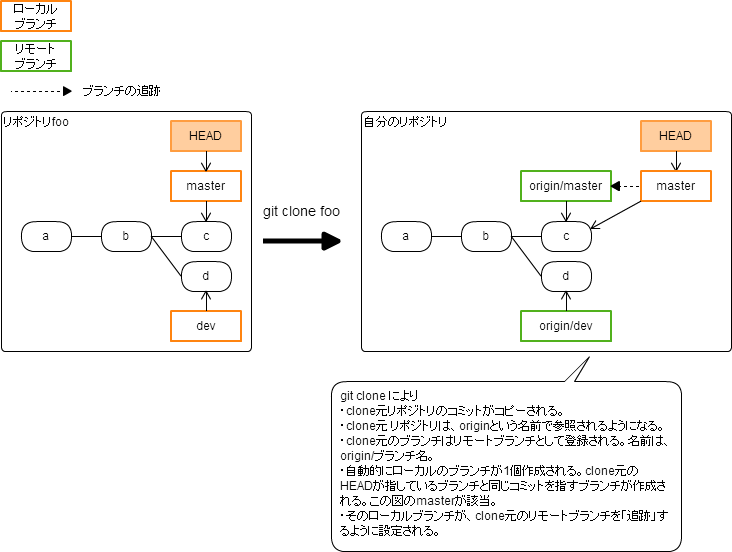
リポジトリは、複数のリポジトリと連携できる。ここで言う連携とは、push/pull(fetch)の相手となることである。複数のリポジトリと連携するため、それぞれに名前を付けて管理する。cloneすると、clone元には"origin"という名前が自動的に付く。名前の一覧表示は git remote で、名前の登録は git remote add で行う。
ローカルブランチとリモートブランチの間に「追跡」関係を設定すると、push/pull(merge)の際の相手が自動的に決定できるようになる。cloneしたときは自動作成されたローカルブランチとリモートブランチとの間に追跡関係が自動設定される。
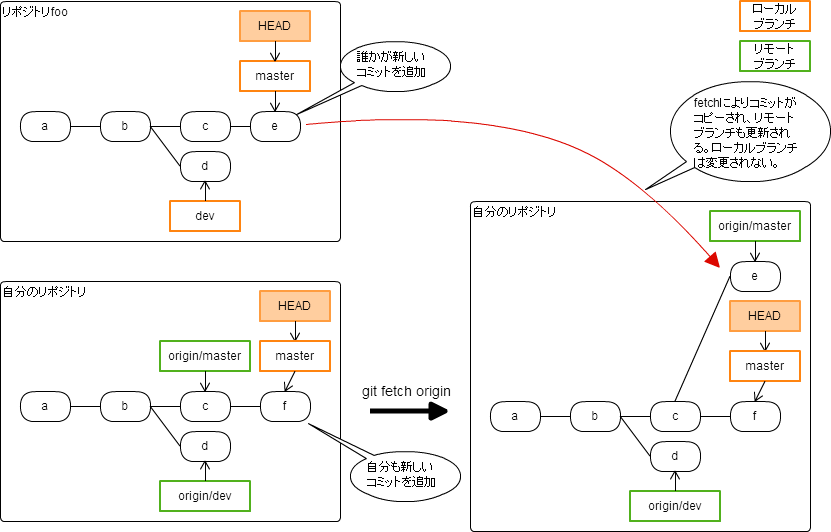
fetch
連携している別リポジトリから内容をコピーするには、git fetch を実行する。
git fetch <リポジトリ>
指定したリポジトリから取得する。
git fetch --all
名前を付けて登録されている(git remoteで登録)別リポジトリすべてから取得する。
git fetch
現在のブランチと追跡関係にあるリポジトリ(と思われる・・・)だけから取得する。
merge
現在のブランチに、指定したブランチの最新コミットの内容をマージする。
git merge <ブランチ名>
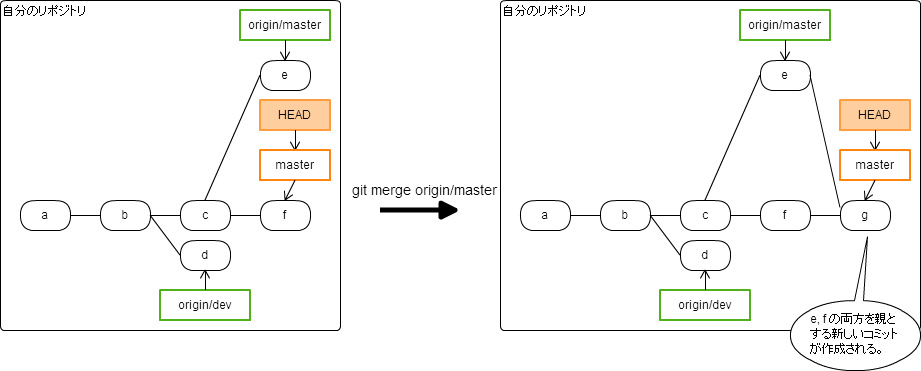
備考
- git merge では、ブランチ名の指定は必須。以下の設定をすると、ブランチ名を省略できるようになり、省略した場合は追跡関係にあるリモートブランチ*1が指定されたとみなす。
git config merge.defaultToUpstream true
- git pull は、fetch と merge をまとめて実行。このときは、ブランチ名の指定は省略できる。
- fetchの実行後に、分岐が発生しているか(mergeが必要か)を確認するには、git status を実行すればよい。次のような形式で表示される。
# On branch dev # Your branch and 'origin/dev' have diverged, ← have diverged = 分岐している # and have 1 and 1 different commit each, respectively. # nothing to commit (working directory clean)
push
別リポジトリに自身の内容を送り出す。

備考
- ブランチを更新していなくても、送出先のブランチが更新されていると(自分のほうが古いと)、pushは失敗する。
- デフォルトでは、ローカルブランチが複数ある場合、それらすべてをpushしようとする。したがって、自分が作業しているのとは別のブランチについて、送出先のブランチが更新されている場合にもpushが失敗する。なお、これは、fetchすれば解消する問題ではなく、mergeが必要である。fetchで更新されるのはリモートブランチであり、push対象となるローカルブランチはfetchしても更新されない。ローカルブランチの内容をリモートブランチと合わせるにはmergeが必要である。
- push時に、作業中のブランチについてのみpushされるようにするには、次の設定をする。この設定により、前述の問題は回避できる。
git config push.default upstream
マージ作業中のdiffとファイル取得
git merge でマージにコンフリクトが生じた場合は、手作業で解消する必要がある。
このとき、ステージング領域には、commit予定のファイルを置く領域とは別に、stage1, stage2, stage3 という、3つの別の領域が設けられる。これら3つの領域とのdiffを確認することで、マージ対象となるブランチそれぞれとの差分を確認できる。
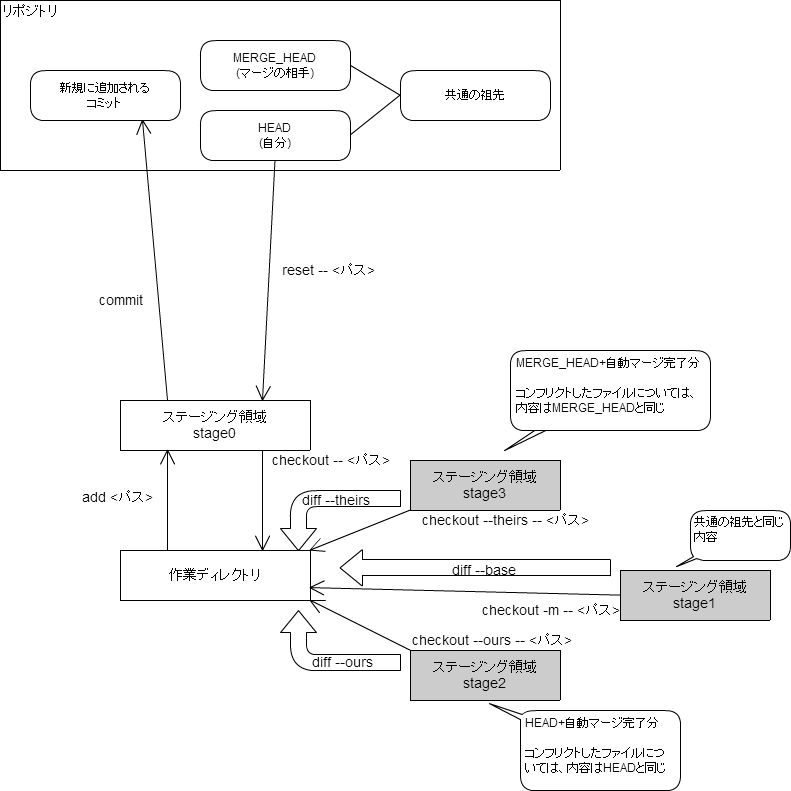
備考
- マージ中は、マージの相手となるコミットにMERGE_HEADという別名が付く。git diff MERGE_HEAD で、マージ相手と作業ディレクトリの差分を確認できる。
- git diff MERGE_HEAD と git diff --theirs (stage3との比較) とは異なる。stage3と作業ディレクトリは、自動的にマージできたものは反映済みである。したがって、git diff --theirs はコンフリクトが生じた部分のみ表示される。MERGE_HEADは、マージ相手そのものである。したがって、git diff MERGE_HEADは、自動マージ済みの部分も差分として表示される。
- 次のコマンドで、statge0〜3のステージング領域のファイルの内容を表示できる。
は0〜3の番号。
git show ::<パス>
- gitがコンフリクトによるマージ中断したファイル(<<< >>> などのマークが入ったもの)を編集後に、編集前の <<< >>>などが入った状態に戻したい場合は、git checkout -- <パス> を実行すればよい。
- マージがコンフリクトした場合で、マージ作業を中断してマージを取り消すには、 git merge --abort
ブランチの操作
一覧
- ローカルブランチ一覧、現在のブランチの確認
git branch
現在のブランチは * 記号付きで表示される。
- ローカルブランチ一覧、最新のコミットコメント付き
git branch -v
- リモートブランチ一覧
git branch -r
作成
- ブランチを作成
git branch <名前> <元のコミット>
<元のコミット>省略時は、現在のブランチを元にする。
- ブランチ作成と同時にcheckout(作業ディレクトリ内容も更新)
git checkout -b <名前> <元のコミット>
branch, checkout -b のどちらの場合も、元のコミットがリモートブランチなら、追跡関係が自動的に設定される。
git push --set-upstream <リポジトリ> <ローカルブランチ>
<リポジトリ>はoriginなど。ローカルブランチと同じ名前で別リポジトリに作成する。
--set-upstreamを付けることで、ローカルブランチと新規追加されるリモートブランチに追跡関係が設定される。
ローカルとは別の名前で別リポジトリに登録したい場合は、
git push --set-upstream <リポジトリ> <ローカルブランチ>:<別リポジトリでのブランチ名>
履歴表示
- 今のブランチのログを表示
git log
今いるブランチのログだけ表示される。
- 別のローカルブランチや、リモートブランチのログを表示
git log <ブランチ名>
連携している別リポジトリのログが参照したい場合は、git fetchで内容をコピーして、git log origin/master のようにリモートブランチ名を指定してログを表示する。
表示内容の選択
- diffも合わせて表示
git log -p
- 変更されたファイルの一覧と変更量も表示
git log --stat
- 1コミット1行で表示
git log --oneline
- 分岐・マージのわかるグラフ付きで表示
git log --graph
表示する履歴の絞込み
- master(の最新)の祖先。ただし、v2.5とその祖先は除く。
git log v2.5..master
v2.5の延長にmasterがある場合は、単純にv2.5の次からmasterまで。途中で分岐してv2.5とmasterに分かれた場合は、分岐地点の次からmasterまで。
- master(の最新)の祖先と、v2.5の祖先。ただし、masterとv2.5の共通の祖先を除く。
git log v2.5...master
途中で分岐してv2.5とmasterに分かれた場合は、分岐地点からv2.5までと分岐地点からmasterまで。
- コミットコメントにfooが含まれるもの
log --grep foo
hg incoming と同様のこと(リモートブランチにあって、自分のブランチに無いコミットを表示)がしたい場合は、git fetchした後で、たとえば次のようにする。
git log HEAD..origin/master
hg outgoing と同様のこと(pushにより送出されるコミットを表示)がしたい場合は、
git log origin/master..HEAD
HEADは省略できるので、これらは単に、次のように実行してもよい。
git log ..origin/master git log origin/master..
*1:このブランチは、.git/configの[branch "ブランチ名"]のremote=とmerge= で指定されている
データベース利用時に自前で排他制御が必要か
並行処理がある環境では、Webアプリに限らず排他制御の考慮が必要。必要になる典型例は次のパターン。
パターン1
- 値を取得してから
- その値に基づく計算結果を書き出し
パターン2
- 前提条件を確認してから
- 条件を満たしていれば処理を実行
1を取得・確認してから2を実行するまでの間に別のスレッド・プロセスがデータを書き換えてしまうと、1で得た情報がもはや正しくないまま2を実行してしまう可能性がある。このため、これらの処理が完了するまでの間に1の結果を変更してしまうような処理が割り込まないよう排他制御が必要になる。
例1
- 預金残高を取得してから
- それに100円を加えた金額を預金残高として記録
例2
- 会員資格が停止されていないことを確認してから
- その会員にサービスを提供
プログラミング言語レベルの制御なら
Javaの場合、同一VM内であればオブジェクトのロックを利用して排他制御が実現できる。
- あるオブジェクトのロックは1スレッドからしか取得できない。
- あるスレッドがロック保持中に別スレッドがロックを取得しようとすると、開放されるまで待たされる。
ロックはsynchronizedブロック/メソッドに入るときに取得され、出るときに開放される。
排他制御を実現するには以下のどちらも、ロックを取得してから処理するようにする。
- 値を取得する側、前提条件を確認する側
- 値を書き換える側、確認結果を変えてしまうような変更を行う側
例えば、
(a) 値を取得する側
synchronized (foo) { // ←ロックを取得
int balance = 預金残高を取得();
if (balance >= 100) {
預金残高を記録(balance - 100);
}
} // ←ロックを開放
(b) 変更を実施する側 (無理のある例だけれど)
synchronized (foo) {
預金残高を記録(0); // 無条件に残高を0円に変更。
}
変更を実施する側もロックを取得する必要がある点に注意する。ロックを取得しなければ、(a)の実行途中で(b)が実行される可能性がある。
トランザクションと排他制御
トランザクションを使えば排他制御される、というわけでは必ずしもない。
例えばPostgreSQLの場合、トランザクションの分離レベル(隔離レベル)によって状況が変わってくる。
- 「シリアライザブル分離レベル*1」を利用した場合は、複数のトランザクションを順次直列に実行したのと同じ結果が得られるとのことなので、排他制御されていることになる。ただし、トランザクションが失敗することがあるため、失敗時にリトライするようなプログラムを書く必要がある。また、ホットスタンバイレプリケーションでは利用できないとのこと。
- 「リピータブルリード分離レベル」の場合、シリアライザブル分離レベルと同様に順次直列に実行したのとほぼ同様の結果が得られるがいくつかの例外もある(まだよく理解できていない)。トランザクションが失敗することがあるため、失敗時にリトライ処理が必要。
- 「リードコミッティド分離レベル(デフォルトの分離レベル)」の場合、あるトランザクションの実行中に別のトランザクションが実行できるし、トランザクションがコミットすれば、その結果は、実行中の他のトランザクションから見えるようになる。排他はされない。
シリアライザブル分離レベルやリピータブルリード分離レベルの利用に伴う制約やオーバーヘッド(リトライの作成、性能劣化)を許容できない場合はリードコミッティド分離レベルを使うことになる。
リードコミッティド分離レベルでは、
- 各問い合わせが実行を開始した時点のデータに基づいて実行する。
なおこの「問い合わせ」がSQL文1個を指すのか、1文中にサブクエリを含むような場合にそれぞれのSELECTを指すのかは、PostgreSQLのマニュアルからは読み取れない。 - 他のトランザクションの変更内容は、それがコミットされれば、見えるようになる。
少なくとも、トランザクション内でSQL文が2個以上実行される場合は、その途中で別トランザクションが割り込んで、参照しているデータを書き換える可能性がある。したがって、自前で排他制御する必要がある。
では、SQL文1文の場合はどうなるか。
UPDATE 同士の衝突
PostgreSQLデフォルトのリードコミッティド分離レベルの場合で考える。
先の例の「預金残高を取得して100円を加えて記録する」はUPDATEコマンド1個で書けてしまう。
UPDATE account SET balance = balance + 100 WHERE account.id = 12345;
すなわち、UPDATE 1個の実行中に値取得、計算、記録という一連の処理が含まれるが、値取得後、計算前に別のトランザクションが割り込み、預金残高を書き換えてしまうことはないのか。
この場合は、次の2つの働きにより、割り込まれる問題はない。順次実行したのと同じ結果が得られる。
- 行レベルロック
行レベルロックにより、同じ行に対する書き込みは、一方のトランザクションが完了するまで他方が待たされる。 - ロック解除後の再読み込み
行ロックにより待たされた場合、相手のトランザクションが完了後、その更新結果に対して処理が適用される*2
このため、
UPDATEとINSERTの衝突
UPDATEがロックしている行をINSERTが書き換えるわけではなく、ロックによる排他は働かない。
基本的にこの2つはお互い待たされずに並行動作する。
次のケースを検討してみる。
- UPDATEの実行途中にINSERTが実行された場合、追加された行の影響を受けるか。
受けない。リードコミッティド分離レベルでは、UPDATEの実行開始時点でコミット済みのデータを利用する。 - INSERTが複数の行を追加中にUPDATEが実行開始した場合、どうなるか。
UPDATEからはINSERTが追加中の行は見えない。INSERT側が明示的にトランザクションのBEGINを実行していなくても、各文ごとにトランザクションが開始され、文の実行終了時に自動的にコミットされる*3。リードコミッティド分離レベルでは、コミットされるまで別のトランザクションからは見えない。
ここまでの範囲では、UPDATEとINSERTが衝突しても、UPDATE→INSERTの順に順番に実行したのと同じ結果が得られる。
INSERTする行が定数として与えられておらず、サブクエリに基づいて内容が決まる場合はどうなるか。非実用的だが次の例を考える。
INSERT INTO account(balance) SELECT balance * 2 FROM account;
UPDATEの実行中にINSERTが実行開始したとする。INSERTが追加するレコードは、INSERT実行開始時点のaccountテーブルに基づいて決定される。まだUPDATEがコミットしていないため、UPDATE実行前の内容に基づいてINSERTされる。一方、UPDATE側も、INSERT実行前のデータに基づいてUPDATEを実施する。UPDATE→INSERTの順、INSERT→UPDATEの順、どちらの順番で実行した場合とも異なる結果が得られる。
UPDATEとDELETEの衝突
DELETEも行レベルロックを取得するので*4、一方の実行中は他方の実行も待たされる。
UPDATE→DELETEの順に実行された場合は、更新した行がすぐ削除される。
DELETE→UPDATEの順に実行された場合、UPDATEは対象から、その削除された行は除外される(仕組みは後述)。
WHEREによる検索結果が変わるような変更との衝突
UPDATEは更新対象行の行レベルロックを取得するので、事前にWHEREに該当する行を検索して、行を特定してから、行レベルロックを取得し、場合によっては待ちに入ることになる。待っている間に別トランザクションが変更を実施し、WHEREによる検索結果が変わってしまう場合はどうなるか。別トランザクションで次のような変更を実施した場合が該当する。
- 行を追加
- UPDATEが更新しようとしていた行を削除
- WHEREで参照しているカラムの値を変更
UPDATEはロックが開放された後、
- 既に検索して特定した行については、再度WHEREを評価して、条件に該当しなくなった場合は更新対象から除外
- それ以外の行については、再検索は実施しない
このため、
- 更新される行は、WHEREの条件を満たしている
しかし、事前に検索しておいた行以外は再検索しないため、
- WHEREの条件を満たす行であっても、更新されない場合がある
ここで問題なのは、UPDATEが待たされることにより「別トランザクション」→「UPDATE」の順に実行されたかと思いきや、実際に得られる結果はそれとは異なる、ということである。もちろん、「UPDATE」→「別トランザクション」の順に実行した結果とも一致しない。「UPDATE」「別トランザクション」を順に実行した場合には決して発生しない結果が生じてしまう。
まとめ
- 「シリアライザブル分離レベル」のような、順列実行との等価性を保証する仕組みを使わない限りは、自前で排他制御が必要。
- トランザクション中にSQL文1個の場合は、自動的に働く行レベルロックが基本的には排他制御として機能するものの、以下の要因により条件によっては順列実行時と同じ結果は得られない。(PostgreSQLのデフォルトの「リードコミッティド分離レベル」の場合の例)
- INSERTは行レベルロックを取得しないため、UPDATE/DELETEとは排他にならない。INSERTで追加される行の内容がテーブル内容から計算されている場合には(サブクエリの利用)、UPDATE前のテーブル内容に基づく内容が、UPDATE後に、UPDATEによる更新を経ないまま残る可能性がある。
- UPDATE/DELETEのWHEREによる検索は、ロックの前に実施される。ロックしてから検索ではない。ロック解放待ちに入った場合、別トランザクションでの変更に伴い、実行再開後はWHEREの検索結果は変わる可能性があるが、再検索はロック前に該当した行のみに限定して実施され、テーブル全体に対しては実施されない。
*1:完全な対応はPostgreSQL 9.1で追加された模様。
*2:http://www.postgresql.jp/document/9.3/html/transaction-iso.html#XACT-READ-COMMITTEDに説明がある。
*3:マニュアルではhttp://www.postgresql.jp/document/9.3/html/sql-begin.htmlの説明中に記載あり。
*4:http://www.postgresql.jp/document/9.3/html/explicit-locking.html#LOCKING-ROWSの「他のトランザクションが共有ロックを保持している行に対して、更新、削除、排他ロックの獲得を行うことができるトランザクションはありません」という説明から判断して。
Eclipse 3.7 + GlassFish 3.1.2.2
Eclipseインストール
http://mergedoc.sourceforge.jp/ より Eclipse 3.7.2 Indigo SR2 Windows 32bit ベース / Pleiades All in One 3.7.2.v20120225 をインストール。JRE同梱版を選択。
- 64bit版は無い模様。
- サイトに記載のとおり、同梱のTomcatに不具合ありとのこと。
GlassFishプラグインとGlassFishをインストール
プラグインとGlassFish本体をまとめてインストールできる。
この場合、サーバービューへの登録も自動的に行われる。
ただし、GlassFish本体はmultilingualではないようで、管理コンソールは英語となる。
- ヘルプ>新規ソフトウェアのインストール
- [追加]をクリック
- 名前:は適当に
- ロケーション: http://download.java.net/glassfish/eclipse/indigo
- GlassFish 3.1.2.2 Application Server runtime にチェック。配下に Oracle GlassFish Server Toolsが含まれていることを確認。
- 署名がないけど続行する?の警告については、[OK]
- サーバービューに Internal GlassFish 3.1.2.2 が追加されていることを確認。
JSPアプリの作成と動作確認
動的Webプロジェクトを作成すればHello JSPなアプリが生成される。
動作確認のため、これを配備して実行してみる。
- ファイル>新規>動的Webプロジェクト
- プロジェクト名: 任意(ex. HelloGlassfish)
- [完了]をクリック
- プロジェクトエクスプローラーで[HelloGlassfish]を右クリック
- 実行>サーバーで実行
- 使用するサーバーの選択:でInternal GlassFish 3.1.2.2 を選択
- [完了]
- GlassFishが起動する。また、Eclipse内のWebブラウザーが開き、Hello World! と表示される。
スクリーンショット付きの手順は以下のサイトが参考になる。
リモートのGlassFishサーバをサーバービューに追加 → 挫折
そもそも対応しているのかどうかが不明だが、可能であるような情報もある。
Eclipse and GlassFish: remote deployment and debugging - Stack Overflow
以下のとおり試したが、成功していない。
サーバー側の準備
サーバー側の設定として、asadmin enable-secure-admin の実行が必要。
これを実行しないと、外部からの管理関係のリクエストを受け付けない。
enable-secure-adminの内容については以下に解説がある。管理関係の通信が暗号化される。Webの管理コンソールもHTTPSになる。
enable-secure-adminの実行には、事前にadminにパスワードを割り当てる必要あり。
adminにパスワード割り当て
asadmin change-admin-password
secure-adminを有効に
asadmin enable-secure-admin
再起動
asadmin stop-domain asadmin start-domain
Eclipse側
- サーバービューで新規>サーバー
- サーバーのホスト名を入力
- サーバー・ランタイム環境には、定義済みのGlassFish 3.1.2.2 を選択
- [次へ]
- 管理者パスワードを入力して、[Ping Server]
- ここで、以下のメッセージが表示される。
- Cannot communicate with ホスト名:4848 remote server. Is it up? Is it secure? (Hint: run asadmin enable-secure-admin)
サーバには以下のログ
User [] from host ホスト名 does not have administration access
Eclipse側には以下のログ (workspace配下の.metadata\.plugins\org.eclipse.ui.workbench\log)
!MESSAGE GlassFish: getVersion3Only is failing=FAILED
その他の選択肢
Eclipse 4.2
開いたファイルの切り替えが重い。
GlassFishプラグインをEclipseマーケットプレースからインストールする
Eclipseマーケットプレースから GlassFish Java EE Application Server Plugin for Eclipse を選択する。
GlassFish v3(3.1.1)インストール、Eclipseプラグイン導入 - Shinya’s Daily Reportで紹介されている方法。
- Eclipse 3.6 Helios用のものがインストールされる。
- サーバービューへのサーバー追加は自前で実施が必要。
- 自前でGlassFish 3.1.2.2をインストールしてサーバービューへ追加しようとすると、上記サイト記載のとおり、追加できない。以下のメッセージが表示される。GlassFish 3.1.1ならこの問題は発生しない。
- 指定したディレクトリーに有効な GlassFish インストールがありません。 「インストール・サーバー」ボタンをクリックしてダウンロードし、そのディレクトリーにインストールしてください。
なお、サーバータイプとしてGlassFish 3.1とGlassFish Server Open Source Edition 3 があるが、違いが不明。
上記サイトでは後者を選択している。前者を選択すると以下の問題がある。
- 起動構成画面のサーバータブで選択肢に目的のサーバーが表示されない。
- 上記が支障となり、前期サイトに記載のコンソール文字化け対策が実施できない。
GlassFishプラグインを 追加サーバー・アダプターのダウンロードからインストールする
- サーバービュー>新規>サーバー
- [追加サーバー・アダプターのダウンロード]をクリック
- Oracle GrassFish Server Tools を選択
こちらの場合は、サーバータイプにGlassfish 3.1.2が追加され、Glassfish 3.1.2.2 が登録できない問題は解消。
起動構成画面でサーバータブで選択肢に表示されない問題は残存。
また、冒頭の方法でインストールしたプラグインよりも古い。
GlassFish本体は自分でインストールしたものを使う
プラグインに添付のGlassFishは管理コンソールが英語だが、自前でmultilingual版をインストールすることで日本語となる。
GlassFishのインストール手順、サーバービューへのサーバー登録手順は基本的には以下の解説のとおり。
GlassFish v3(3.1.1)インストール、Eclipseプラグイン導入 - Shinya’s Daily Report
差分や補足
- GlassFishのインストール
- ダウンロードするバージョンは3.1.2.2。
- インストール時、adminのパスワードを設定するが、空欄のままでもよい。
- Eclipseサーバービューでの設定
- サーバービュー>新規>サーバ
- サーバータイプは GlassFish 3.1.2.2 を選択。
- サーバーラインタイム環境:に事前登録済みのGlassFish 3.1.2.2 が表示されている。これは使わず、その右の[追加...]をクリック。
- 新規サーバーランタイム環境 のダイアログが表示される。アプリケーションサーバー・ディレクトリー欄にGlassFishのインストール先のglassfishフォルダを指定。(ex. C:\glassfish3\glassfish)
- デフォルトではGlassFish adminにパスワード指定しない設定になっているため、GlassFish adminにパスワード設定時は、次の設定をする。
- サーバービューで、今追加したサーバーをダブルクリック。
- アプリケーション・サーバのグループの[管理コマンドに匿名接続を使用]のチェックをはずす。
- Ctrl+Sで保存
サーバー起動時に以下のエラーが出る場合は対処が必要。
GlassFish v3 requires a JDK 1.6 and not a JRE. Please add/select the correct JDK in the Server properties 'Runtime Environment' section.
- サーバービューで、今追加したサーバーをダブルクリック。
- [ランタイム環境:]というハイパーリンクをクリック。
- JRE: 欄に選択されているものをJDKに変更。選択肢に[デフォルトJRE]以外にjava5, java6, java7があるはずで(Pleiades All in Oneの場合)それらを選択すればよい。
[デフォルトJRE]しかない場合は実行環境としてのJDKを登録する必要がある。
- メニューバーから ウィンドウ>設定>Java>インストール済みのJRE
- [追加]
- 標準VMを選択し、[次へ]
- JREホーム:に、JDKのフォルダを指定。Pleiades All in Oneなら、C:\bin\eclipse-pleiades-java-3.7.2\java\6 など。指定するパスに\jre を付けない。
JDK登録後、前述のように[ランタイム環境:]をクリックし、JRE:欄に、今登録したJDKを選択する。
サーバー起動時になかなか起動が完了せず、コンソール(Server.log)に以下のメッセージが出る場合は、adminの認証情報に誤りがある。
情報: ホスト127.0.0.1のユーザー[admin]が管理アクセス権を持っていないか、不正なユーザー名およびパスワードが指定されています
情報: ホスト127.0.0.1のユーザー[]が管理アクセス権を持っていないか、不正なユーザー名およびパスワードが指定されています
特に、GlassFish側でadminのパスワードありにしている場合、前述のとおり[管理コマンドに匿名接続を使用]のチェックをはずす必要があるが、はずれていない場合にこの現象が発生する。


Swing/AWTで重複する再描画イベントを1つにまとめる仕組み
関係していそうなクラスメモ
LGPLなライブラリを使ってアプリを開発し、配布したい
LGPLv3なライブラリFooを使ってアプリを開発した。
開発したアプリを配布したい。(開発したのはFooを利用したライブラリではなく、Fooを利用したアプリである。)
配布するときに、自分で開発したアプリと共に、そのライブラリ(foo.jar)も一緒に配布したい。
ライブラリFooは自分で改変していないものとする。
守らなければいけないことは何か。
GNU LGPLv3 日本語訳
GNU GPLv3 日本語訳
以下の理解であっているんだろうか・・・
用語との関係
| LGPLの用語 | 本ケースでの該当物 |
|---|---|
| 『ライブラリ』(The Library) | ライブラリFoo |
| 『アプリケーション』(Application) | 自分で開発したアプリ(自分で作った部分) |
| 『結合された作品』(Combined Work) | 自分で開発したアプリ(ライブラリFooとあわせた総体)=配布しようとしているモノ |
守らなければいけないこと
- 配布物に含まれるライブラリFooの改変を許す
- (自分で作った部分も含め?)リバースエンジニアリングを許す
- ライブラリFooを使っていること、ライブラリFooがLGPLv3で保護されていることを配布物内で目立つように告知
- 配布物にGNU GPLとLGPLv3文書を添付
- アプリ実行中にコピーライト告知を表示するときには、ライブラリFooの著作権の告知と、GNU GPL/LGPLv3文書の所在(配布物に添付された文書が配布物中のどこにあるかということ?)を表示
以上は、LGPLv3の4章冒頭の段落と、a),b),c),e)に対応。
d)については、ライブラリの結合の仕方に依存するものだが、JavaのJARによるライブラリ利用の仕組みはd-1)に該当するといえそう。JARを使う限りはd)はクリアできる。
4章e)の要求する『インストール用情報』の提供が必要かどうかが良く分からない。
提供が必要となる条件として、
またそのような情報が、『リンクされたバージョン』の改変されたバージョンと『アプリケーション』を再結合ないし再リンクすることによって作成された『結合された作品』の改変されたバージョンをインストール、実行するのに必要とされる限りにおいてのみである
とある。ライブラリFooの別バージョンに入れ替える場合に必要ならば(『インストール用情報を』提供せよ)、ということになる。別バージョンに入れ替えるにはfoo.jarを置き換えるだけでよく、それ以外に必要な情報はない。foo.jarの置き換え方法の説明を提供する必要がある、ということなのだろうか。
LGPLv3がGPLv3に対する差分(追加の許可)として定義されているため、foo.jarを一緒に配布することに関して、GPLv3の6章の条件を守る必要があると思われる。
- ライブラリFooのソースの提供
提供方法についてはGPLv3の6章のとおり複数の選択肢がある。必ずしも配布物に含める必要はなさそう。
許可されていること
「守らなければいけないこと」を守る限りは何でも?
LGPLv4の4章
あなたは、『結合された作品』に含まれる『ライブラリ』部分の改変を事実上禁止したり、そのような改変をデバッグするためのリバースエンジニアリングを禁止したりしない限り、『結合された作品』をあなたが選択したいかなる条件の下でも複製、伝達して構わない。ただしその場合、以下をすべて行う必要がある:
したがって、以下は可能と思われる。
- 有償で配布すること (GPLでも許可されている。(GPLv3 4章))
- ライブラリFooの除く部分(自分で作った部分)について、
- 再配布を禁止すること
- ソースを非公開とすること
- 改造を禁止すること
参考: The LGPL and Java - GNU Project - Free Software Foundation
Visual Studio 2005 (C++) + eclipse 3.5 で JNIを使ったアプリの開発
JNIを使って連携するJavaアプリとWindowsネイティブアプリ(DLL)を開発する場合の、Visual C++と eclipseの設定について。
eclipseの設定
以下の設定をする。
ヘッダ生成用build.xml
例として、ヘッダ生成先を(プロジェクトのフォルダ)\includeとする。build.xmlの作成場所は任意。
<?xml version="1.0" encoding="UTF-8"?> <project basedir="."> <property name="class.dir" value="${basedir}/bin"/> <property name="javah.path" value="C:\Program Files\Java\jdk1.6.0_16\bin\javah"/> <property name="header.dir" value="${basedir}/include"/> <target name="create.header.files"> <javah class="mysample.Sample"/> <javah class="mysample.Sample2"/> </target> <macrodef name="javah"> <attribute name="class" /> <sequential> <echo>Creating a header file for @{class}</echo> <exec executable="${javah.path}"> <arg value="-classpath"/> <arg value="${class.dir}"/> <arg value="-d"/> <arg value="${header.dir}"/> <arg value="-jni"/> <arg value="@{class}"/> </exec> </sequential> </macrodef> </project>
javah.pathプロパティには、JDKが提供するjavah.exeのパスを定義。
javahタグのclassアトリビュートには、ヘッダの作成対象となるクラス名を記述。
DLLの検索パス
DLLの検索パスは、後述のVisual Studioのプロジェクトを作成した後で、以下のとおり設定。
- 一度 [Run] > [Run]で実行させるなどして、configurationを作成する。
- [Run] > [Run Configurations...]で当該のconfigurationを選択。
- [Environment]タブで[New...]をクリック
- 以下のとおり入力してenvironment variableを追加
- Name: PATH
- Value: (Visual Studioのプロジェクト作成時に指定したパス)\debug
上記の"debug"の部分は、Visual Studioのプロジェクトでビルドするときのソリューション構成に合わせる。ソリューション構成が「Debug」の場合はdebug, 「Release」の場合はrelease。ソリューション構成はVisual Studioの[ビルド]-[構成マネージャ]で選択。
Visual Studioプロジェクトでは同じ名前のフォルダが別の階層に作成されるため紛らわしい。Visual Studioプロジェクト作成時に、[場所]をc:\foo、[プロジェクト名]をbarとすると、以下のようなフォルダ構成が作成される。
c:\foo
+-- bar
+-- bar
| +-- Debug
| +-- Release
+-- debug
+-- release
DLLが作成されるのはc:\foo\bar\bar\DebugではなくC:\foo\bar\debugなので、
envitonment variableのPATHにもC:\foo\bar\debugを指定する。
Visual Studioの設定
以下の設定をする。
- DLL開発用のプロジェクトを作成する。
- 文字セットはUnicode(1文字2バイト)
- JDKが提供するjni.hがインクルードできるようにする。
- JDKが提供するjvm.libがリンクできるようにする。(JNIの「呼び出しAPI」(ネイティブ側からJVMを呼び出すAPI)を使う場合にのみ必要)
具体的な設定内容は以下のとおり。
- プロジェクトの作成は[ファイル]-[新しいプロジェクト]で[Visual C++]-[Win32]の[Win32プロジェクト]
- 「Win32アプリケーションウィザード」が表示されたら[次へ]。アプリケーションの種類は[DLL]。[空のプロジェクト]、[シンボルのエクスポート]はチェックなし。[ATL]、[MFC]は必要に応じて(チェックなしで良い)。
- ソリューションエクスプローラーのウィンドウで、作成したプロジェクトを右クリックして[プロパティ]
- 表示されたプロパティページで、上部の[構成]から[すべての構成]を選択
- [構成プロパティ]-[全般]の[文字セット]は[Unicode文字セットを使用する]
- [構成プロパティ]-[C/C++]-[全般]の[追加のインクルードディレクトリ]に以下の3つを追加
- [構成プロパティ]-[リンカ]-[全般]の[追加のライブラリディレクトリ]に以下を指定
- (JDKインストールフォルダ)\lib
- [構成プロパティ]-[リンカ]-[入力]の[追加の依存ファイル]に以下を追加
- jvm.lib (パスはつけない。[追加のライブラリディレクトリ]に指定したディレクトリから検索される。)